Answers range all over the place and none of them are great, i’m wondering if anyone has an opinion on the most native, elegant and readable way to simulate multidimensional objects in BASH?
# Single dimension associate arrays are good to go.
declare -A linuxPhones=(\
[pinephone]='pinephone-test'\
[librem5]='librem-test'\
)
for phoneName in "${!linuxPhones[@]}"; do
echo "${phoneName} = ${linuxPhones[$phoneName]}"
done
# Output:
# librem5 = librem-test
# pinephone = pinephone-test
# Can't declare an array within an array:
declare -A linuxPhones=(\
[pinephone]='pinephone-test'\
[librem5]='librem-test'\
)
declare -A linuxPhones[pinephone]=(\
[gpu]='MALI-400MP2'\
)
# Output:
# linuxPhones[pinephone]: cannot assign list to array member
You can use arrays in Bash, but there is no dictionary or hash data type in Bash. Usually, when you get to the point of needing a stronger data type most people move to Python ( or another language with stronger data types ).
I float between the two depending on the requirements of the project I’m working on.
Really ugly (but working) scratch code for testing a concept.
eval on demand with a _ deliminator for simulating hierarchy.
declare -A linuxPhones=(\
[pinephone]='\
[gpu]="MALI-400MP2"
[screen]="\
[in]=5.95\
[x]=720\
[y]=1440\
"\
'\
[librem5]='\
[gpu]="Vivante GC7000Lite"\
[screen]="\
[in]=5.7\
[x]=720\
[y]=1440\
"\
'\
)
for i in "${!linuxPhones[@]}"; do
VAR_NAME="linuxPhones_"${i}
eval "declare -A $VAR_NAME=(${linuxPhones[$i]})"
done
for i in "${!linuxPhones_pinephone[@]}"; do
VAR_NAME="linuxPhones_pinephone_"${i}
eval "declare -A $VAR_NAME=(${linuxPhones_pinephone[$i]})"
done
SCREEN_X=${linuxPhones_pinephone_screen[x]}
SCREEN_Y=${linuxPhones_pinephone_screen[y]}
echo pinephone screen has $(($SCREEN_X * $SCREEN_Y)) pixels!
# Output:
# pinephone screen has 1036800 pixels!
I usually jump to Python pretty quickly from a Bash project these days. I didn’t used to until I considered how frustrated I would sometimes get trying to find a solution to weird use-case that I wanted to get done quickly with Bash.
For me, some things are just easier in Python. That’s usually because of the vast library of modules available for Python.
I used to struggle with deciphering nested json data structures that I would get back from some applications API until I ran across a YT video showing how Jupyter Notesbooks automatically formats the output from json and provides a visual view of the structure…all part of the learning process.
@Ulfnic you have surpassed my expertise with Bash…I need to write more Bash scripts.
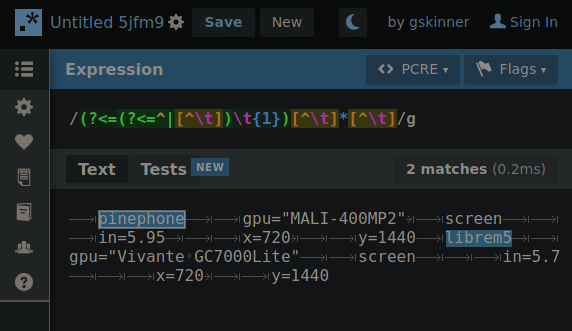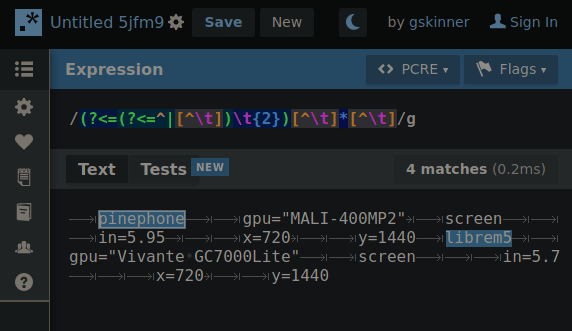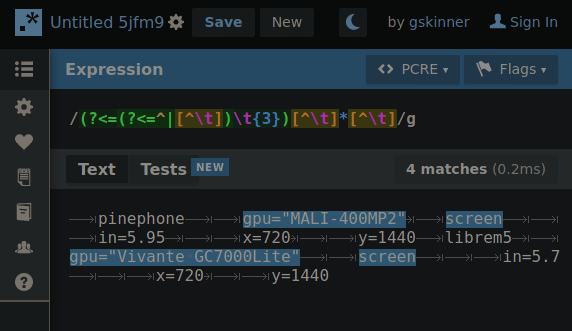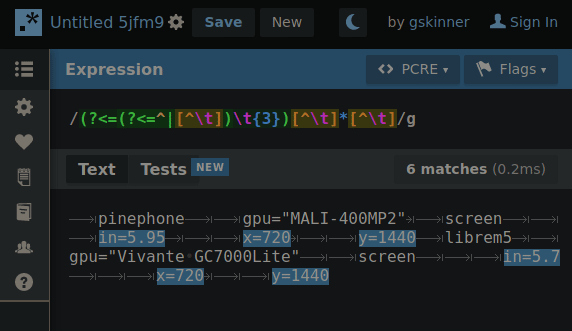
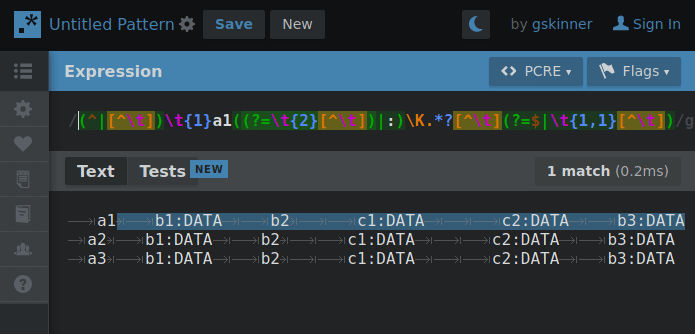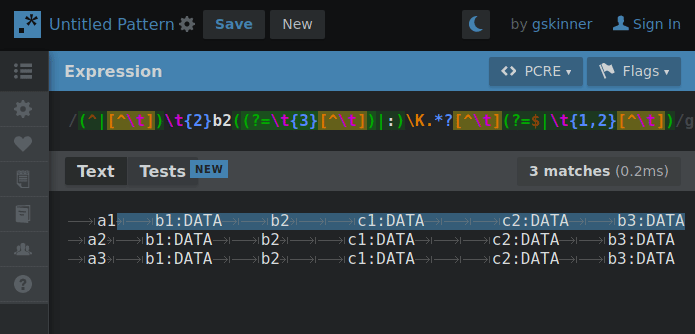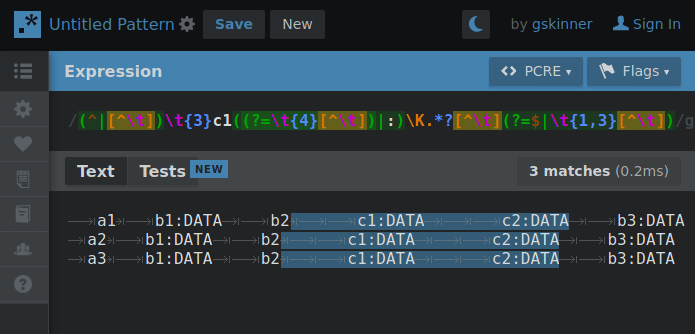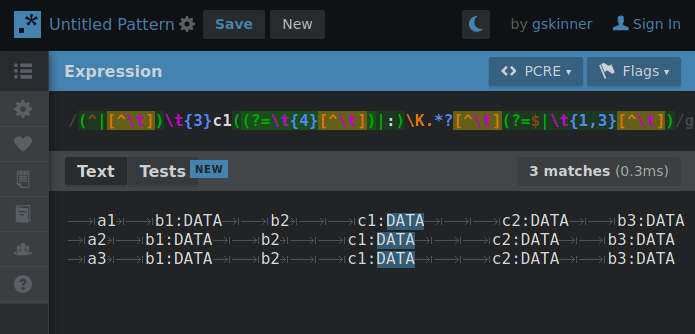
Experimenting with hierarchical tab delimitation (yes I made that term up) I made this RegEx that’d allow me to cycle through each layer so requests for property values could “find” their way through the hierarchy with the aid of some string cutting.
(Excuse the duplicate info on both phones, I just needed copy/paste filler)
Notice “Javascript” in the drop down menu…
I’ve only used simple RegEx in terminal so I wasn’t aware there’s lots of different types of RegEx that interpret differently. This RegEx I wrote can’t be used in native Linux unless I install an interpreter like nodejs.
My newb explanation (if i’m correct): Native Linux uses POSIX.2 regular expressions…
The problem being there’s no “positive look behind” as i’m using here (?<=(^|[^\t])\t{1}) which i’m depending on for matching against specific tab patterns without including them in the property result. I can probably pull this off in POSIX.2 but i’ll need to pass it through extra layers to get the same result. ARG!!!
Most distros also package PCRE (Perl-compatible regular expressions) libraries which may save the day, we’ll see…
I like BASH for it’s hyper-accessibility, hackability and readability (assuming care is taken to keep it readable and short). It’s got a certain purity to it and translates 1:1 to general terminal use.
Anyone who’s new to Linux can just copy/paste it right off the forum, hack on it and run it with no dnf/apt, no compiling, just plain fun.
That said… yeah it’s bash lol…
Use the right tool for the right job, if it’s a screw use a screwdriver don’t bash it in with a hammer.
I learned regex back in the day when I was scripting in Perl. Man, that was a long time ago ( 2004, maybe, I can’t remember ).
I’m not a regular user of Jupyter, but for visualizing json data structures, it can really be helpful. For smaller data structures you can also get away with Python’s pretty print ( pprint ) function.
I used to be one of those that would common pull data into Excel so that I could do whatever I needed to it, sort, count items, remove duplicates, whatever was needed. These days, I’m more apt to get the data into Bash so that I can use awk, cmp, cut, diff, sed, sort, tr, uniq, etc to do the exact same things, but doing them from Bash helps me learn and keep my skills sharp enough for when I need to automate the data munging.
@Ulfnic don’t forget about popd and pushd while you are working with those arrays in Bash.
PCRE has “positive lookbehind” but my Javascript RegEx didn’t work in PCRE. A great deal of tinkering later I discovered Javascript will apply a parent group type to all nested groups where PCRE needs them individually defined. The result is RegEx that works in both JS and PCRE.
(?<=(nested…changes to (?<=(?<=nested…
The plan:
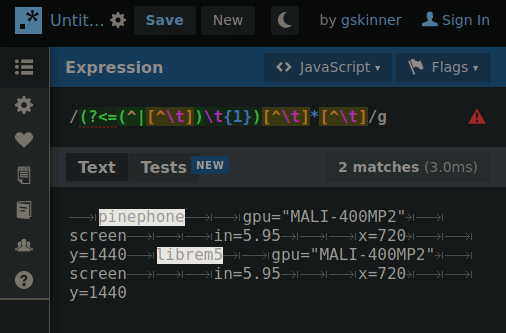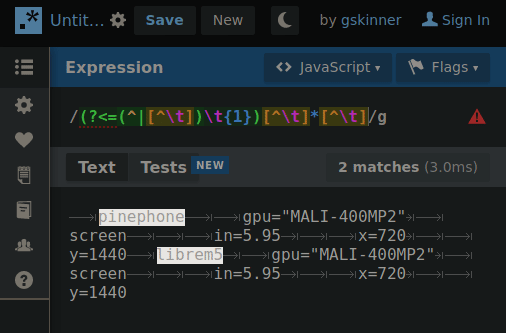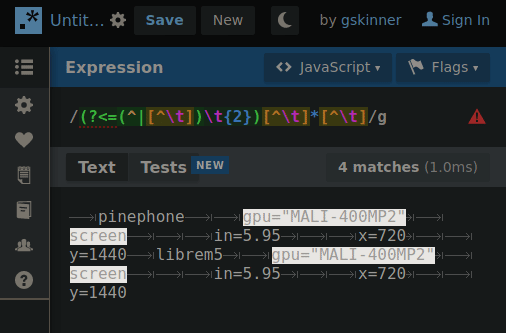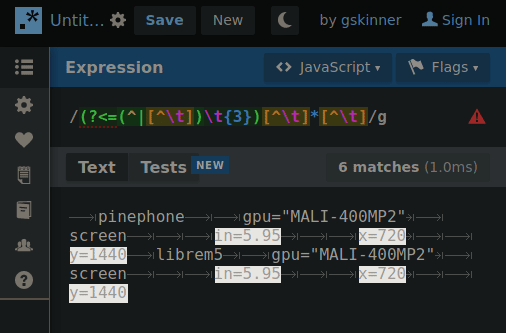
By changing 1 number, the RegEx will “climb” the tab deliminated heirarchy so if the string is cut between a matching property and the next property on the same level… when the number increments the next search will only include properties in the matched portion of the heirarchy.
That’s just some of them. There are many. I need more practice with awk and sed. Those two are very easy to use for simple use cases, but can get very complex.
Oh, and I left out the most important Bash cmd/tool…grep.
I built a more complicated test heirarchy and my RegEx broke in spectacular ways. I was also able to clean things up with the \K command (assuming KDE influence) which “cuts” out everything previously matched from the result so I could clean up the “lookbehind” section.
Turns (?<=(?<=^|[^\t])\t{1}) into ((^|[^\t])\t{1})\K
Improvements:
Property name encapsulation is now explicitly defined. They must start at the beginning of the doc or ahead of a tab and end in either the exact amount of tabs required for containing properties or with a : identifying they have a simple value. This allows them to be empty (result is non-existing), prevents partial matches being treated as full matches and generally makes the syntax more robust.
Now accepts a search term for the property name.
Now “cuts” the relevant information for the next level search. No need to pipe into a second command.
Now recognizes end-of-file for encapsulation and not just tab. Would break search under certain conditions.
Now explicitly requires the number of ending tabs be equal to or below the level of the property. This used to break the cuts if the hierarchy wasn’t always climbing.
“lookbehind” cleaned up with -K. Need to do speed tests but it makes life easier for now, easy to revert to (?<=.
GIF below shows an example of iterating through the layers making the correct cut for the next layer search. You’ll need to imagine the next search only using what was highlighted in the previous.
Presently the RegEx is fully capable of picking any one value out of this syntax if the result of each level’s search is fed into the next. The command to return the value would look something like: $(MY_SEARCH_FUNC a2 b2 c1) # Returns “DATA”
I agree that bash has a limit to how far you can get fancy, and once things get too difficult in bash, then it’s time to move up to something like Python.
In bash, I mostly just do for-loops, while-loops, and shell-expansions (using wildcards), when it’s time to get fancier. I know a handful of keyboard shortcuts as well, and that’s how far I’ve taken it. Having said this, bash is indeed my favorite shell.