Last weekend my main HDD started failing and my 20 years old backup server did not boot anymore. I kept calm, because I had a 2nd backup on my 11 year old laptop with a new 2TB HDD.
But first the problems with my desktop HDD. I run OpenZFS everywhere. I have 2 HDDs (1TB and 500GB) having 3 partitions of ~500GB. I have to admit, that I did take some risk, since the 500GB Seagate Baracuda I bought in 2014 and has close to 9 power-on years and the WD Black I bought “refurbished” in 2018 and had close to 10 power on years.
The problem occurred on 2 striped partition of 500GB. The 500GB Partition of the 1TB disk had been declared degraded by ZFS and it only allowed reads from that partition and all writes were done to the other HDD; smart ![]() I did run the utility badblocks and indeed it did find 4 sets of consecutive bad blocks. Now I did run into 2 different philosophies about disk errors:
I did run the utility badblocks and indeed it did find 4 sets of consecutive bad blocks. Now I did run into 2 different philosophies about disk errors:
- the HDD firmware only declares a bad sector and reallocates the sector, when more than 1 write causes read errors afterwards. Sometimes another write solves the problem and they don’t want to have too many bad sectors, giving the brand a bad name.
- OpenZFS top priority is data integrity, so they refuse to write to a HDD with problems, so the faulty sectors will never be rewritten and consequently they can’t be reallocated by the HDD firmware to another spare sector. As a consequence we have a catch-22 situation. I tried to solve the situation by running the badblocks utility using a write with different patterns, but that would take 2 days and after the first power-fail of the ~20 per week, I did give up.
Of course my Saturday backup failed due to read errors on the dataset with the faulty sectors. ZFS informed me that the Virtual Machines; Windows 10 Pro; Windows 8.1 Pro and Ubuntu Unity 22.04 LTS had read errors. Giving the catch-22 situation and the age of the HDD, I decided to replace the disk by a 2TB Seagate Baracuda NEW this time. I copied all the data from the old disks to the new one and fortunately even from the dataset with the read errors a week old snapshot was still readable.
So from now on for me; snapshot = backup.
Of course I had to rerun all OS updates of the Virtual Machines again. Afterwards I did backup that dataset to the backup on my laptop, so my first backup was complete again. The backup to my backup server failed, the system did not boot anymore and I did run into two problems.
The power-supply failed one week earlier and I combined 2 power supplies to one working one, but I did forget that the power supply had problems in the past with the startup current of the 4 HDDs (2 IDE 3.5" and 2 SATA-1 2.5"). I had to connect 1 IDE desktop HDD and 1 laptop HDD on each disk power cable. It is not all hopelessly old, since the 4 HDDs have between 1 and 3 power-on years and they are nowadays powered on for say 2 hours/week.
Afterwards I did run into problems with the memory, I had two dual rank DDR cards and one single rank and the system refused to work with that configuration, so I reduced memory from 1.5GB to 1GB.
Finally my backup server received the the last part of the outstanding backup again. I can’t complain too much, because the backup server is close to 20 years old.
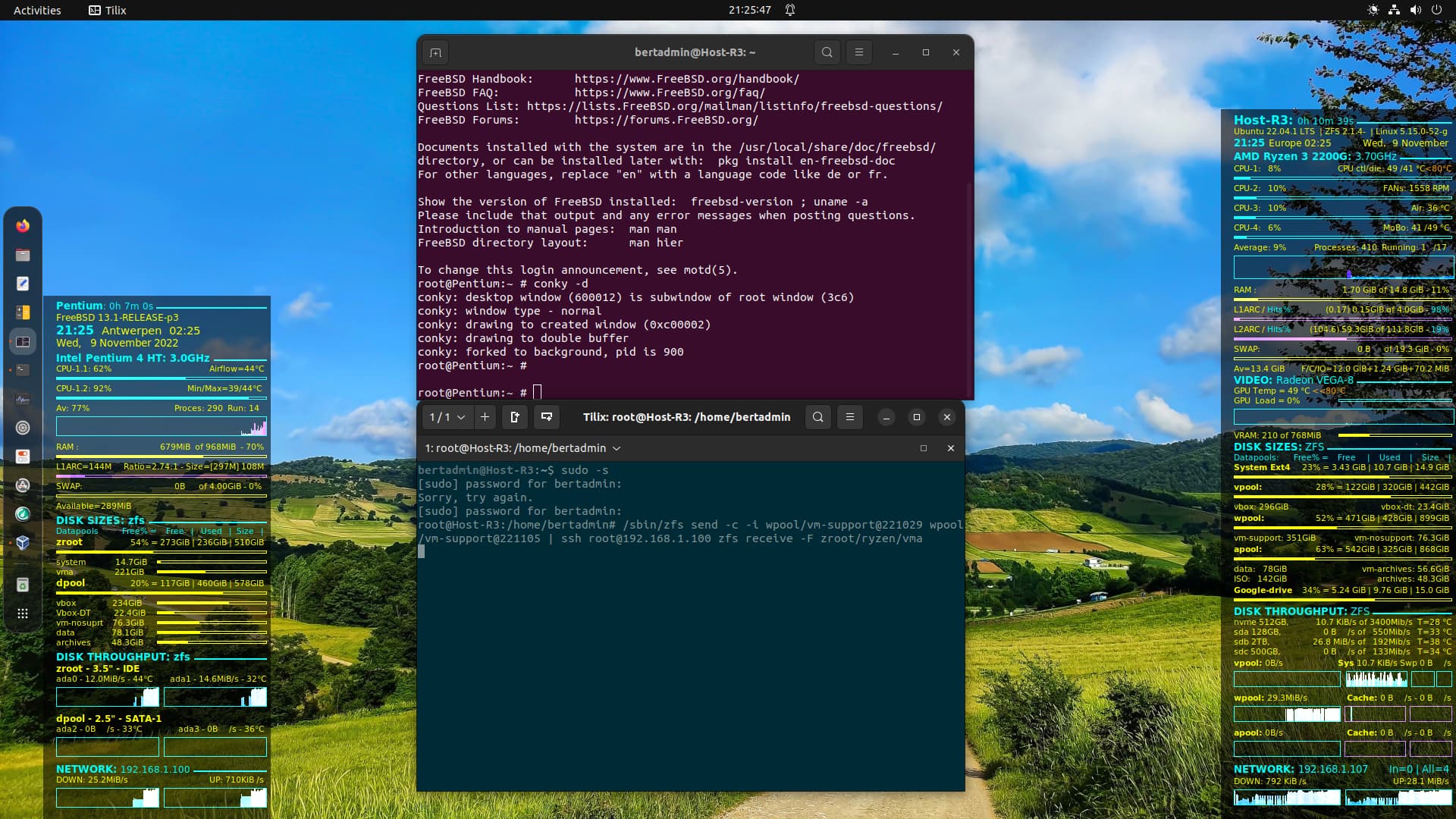
On the left you see the conky display of the backup server and on the right the conky display of the desktop. Purple is the SSH display of the backup server and green the one of the desktop with the zfs incremental backup command.
Note that I still use the 500GB HDD, basically because two dataset in total 200GB (ISO files & ancient VMware VMs) were missing from my backup-server due to lack of space and I backup those on to the 500GB HDD now.