UNDER CONSTRUCTION
I boot and run Ubuntu 21.04 Beta from OpenZFS 2.0.2 and I like to share the marvelous performance of my cached good old HDDs.
I think boot times give a first idea of the performance during normal operation for home usage. I measured the following boot times for a virtual nachine:
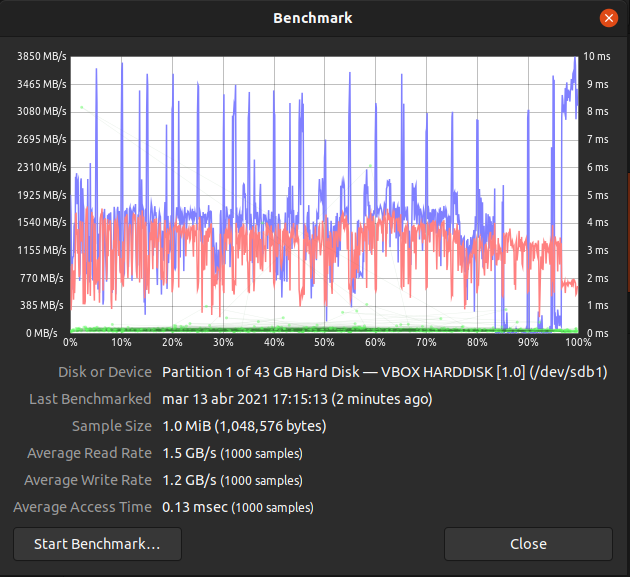
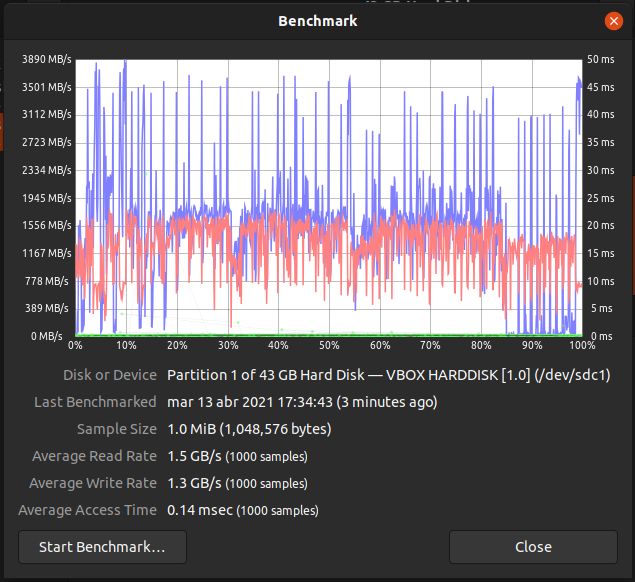
Ubuntu 21.04: Boot times nvme-SSD vs RAM + SSD cached HDDs = 13.8 vs 15.5 → 12% differences of performance.
Those HDDs are my 500 GB Seagate Barracuda (7.8 power on years;135MB/s; 15.3 msecs average seek time) and my 1 TB WD Black (8.5 power-on years; 106MB/s; 10.3 msec average seek time). Both drives will switch off, if not used during 5 minutes and both drives are used for less than 10% of the time. Almost all my IO is done by my 512GB nvme-SSD (Silicon Power; 3400/2300MB/s).
My main hobby is collecting Virtual Machines (VMs) and as such I have for example all Windows versions from the last 35 years, starting with Windows 1.04 to Windows 10 and all Ubuntu LTS releases from 4.10 to 20.04 LTS and 21.04 Beta.
Both HDDs have a striped 420GB partition, the 500GB HDD has some additional small partitions for recovery like an ext4 based Ubuntu 20.04 LTS installation.
I have added a sata-SSD for caching (Silicon Power 128GB; CDM: 500/450MB/s). For the two striped partitions I have added a 90GB sata-SSD cache (L2ARC) and for the remaining partition of 580GB of the 1 TB WD Black, I have added a 30GB L2ARC. The 8 GB remainder of the SSD is used for synchronous write cache.
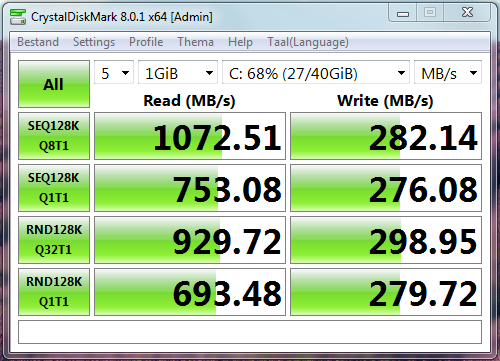
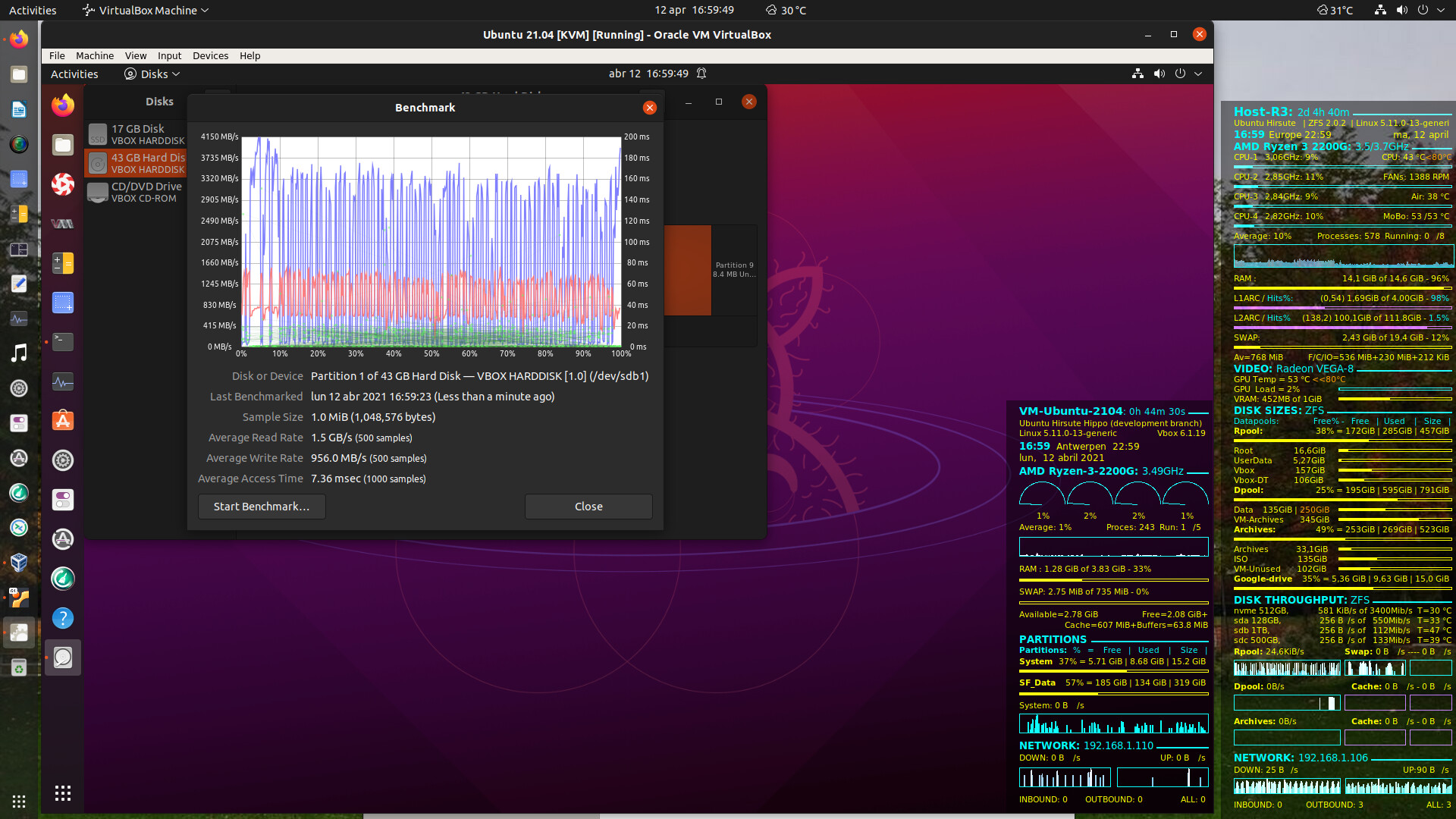
The performance of those ancient HDDs is amazing, see the screenshot:
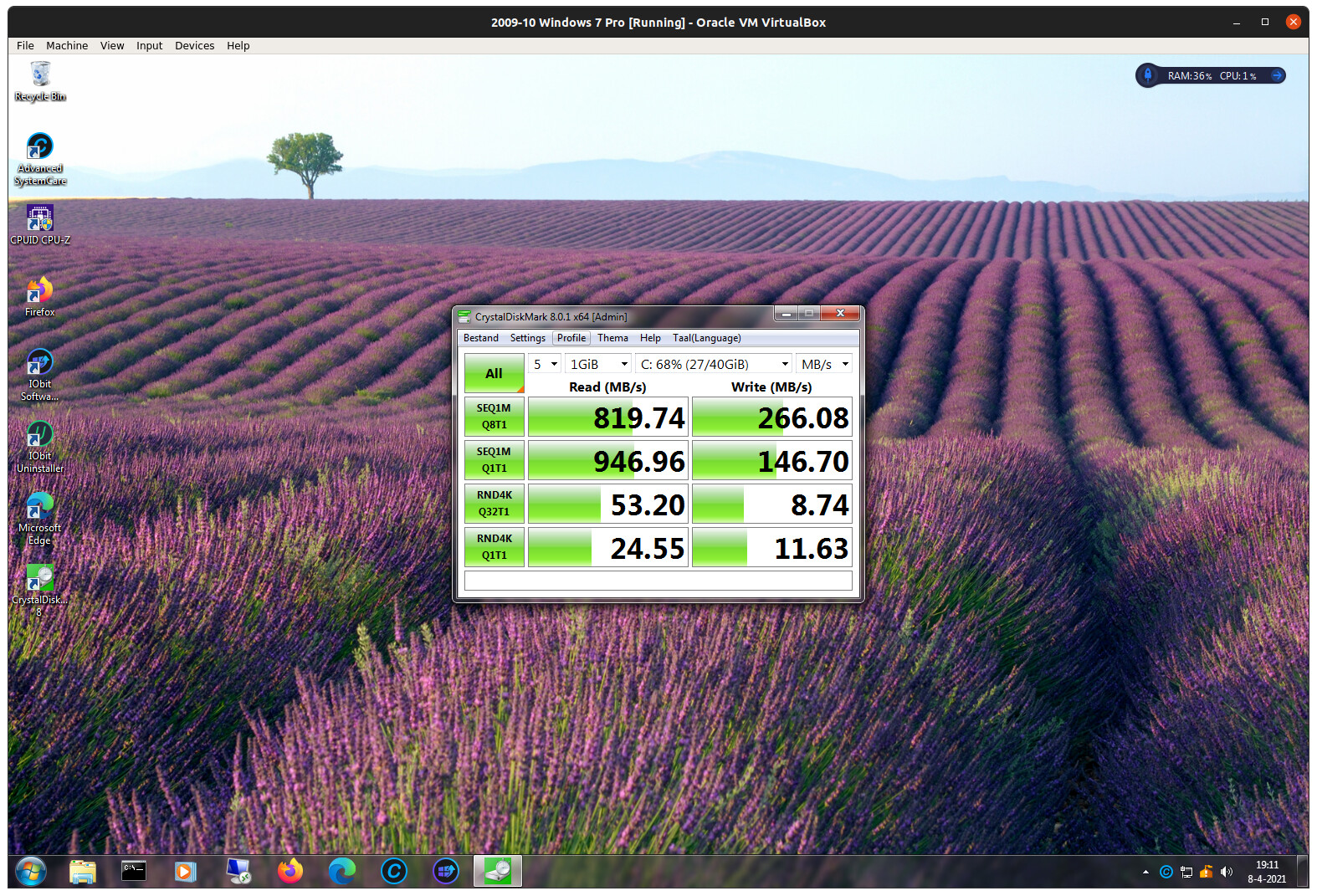
In the middle we can see ChrystalDiskMark running on a Windows 7 Virtual Machine with the values achieved by those old HDDs assisted by the 2 caches. The sequence is
Virtual Disk (.vdi) —> L1ARC (memory 4GB) —> L2ARC (SSD 90GB) —> striped HDDs (840 GB).
For all read operations it has the advantages of:
- both caches L1ARC (Hit Rate >97%) and L2ARC (Hit Rates from 2% up to 50%) and
- all data is lz4 compressed with a typical compression ratio of ~1.8.
For the sequential reads it achieves a performance close to some of the cheaper nvme-SSDs! After the second run say 98% of the data is read from the L1ARC, thus from memory. The Host ZFS system has to find the compressed data in the cache, decompress it and transfer it to the CDM program in Windows 7, there is no physical IO involved. I see the same effect starting e.g Firefox in a VM, the first time it must be read from L2ARC (SSD cache) or from the striped HDDs, so you notice it. Afterwards reloading Firefox is instantaneous. The 15% difference between Q1T1 at 947 MB/s and Q8T1 at 820 MB/s is difficult to explain. I expect, it has to do with peak CPU loads, when firing 8 IO operations at once, instead of one at a time.
For the random read operations the throughput looks worse, but to give CDM one uncompressed 4K record, ZFS has to read a compressed 128k record from one of the 2 caches or from the striped HDDs. When correcting for the record size the Host OS deals internally for Q32T1 with 128/4 x 53 MB/s is ~1702 MB/s, but in the Host those records are compressed so we are dealing with 1702/1.8 is ~946 MB/s, which is again very close to the values for sequential IO. Since no physical IO is involved, we are only dealing with reading data from the memory cache and those basic values should be more or less the same for all types of operations, the only difference is the OS & ZFS overhead involved for the different record sizes and queue depths.
For RND4k Q1T1 the values are 128/4 x 24.55 / 1.8 is ~436 MB/s, which is approx half of all other values. We have to realize that the before mentioned overhead is maximal, if you want to read 1 GB of 4k records one at a time.
For the write operation it has no advantage from the L2ARC and it uses the following hardware:
Virtual Disk (.vdi) —> L1ARC (memory 4GB) —> striped HDDs (840 GB).
ZFS for its write cache (LOG/ZIL) only supports synchronous writes and none of the writes used by CDM are synchronous writes. For write-operations the L1ARC collects for 5 seconds all writes, compresses them; sorts them based on the location on the platters and then writes them out in one sequence of IO operations directly to the striped HDDs. For the 2 HDDs the theoretical read throughput is 240MB/s, let’s assume the theoretical write throughput is 75% of the read throughput so 180MB/s.
Sequential Write Q8T1 (Eight write operation of 1 MB are Queued using 1 Thread) seems to run at 266 MB/s. The Host is compressing each record and writes the compressed records to disk, so it runs at 266 / 1.8 = 148 MB/s
Sequential Write Q1T1 (One write operation of 1 MB is Queued using 1 Thread) runs at 147 MB/s, taking compression into account it runs at 147 / 1.8 = 82 MB/s. The values seem correct, since I have seen this type of throughput also during normal operation. If I compare it with the theoretical write speeds, they seem realistic too. However I can’t explain the difference, since normally for single HDDs those two values are almost equal. Maybe the difference can be explained by:
- The HDDs are striped, so a seek operation on one disk can be done in parallel with read operations on the other. That parallelism would probably be more effective with Q8 than with Q1.
- The OS/ZFS overhead for dealing with 8 sequential operations at once or 1 operation per time.
- The number of HDD seek operations needed might be different based on the queue depth.
For the random write operation the throughput is a factor 10 better than for a normal single HDD with CDM. The write operation must be done to different location on both striped disks.
So we have to take into account the times for:
- the OS/ZFS latency for the write operation
- The seek/access time to the different locations on the disk on average for my 2 disks ~12msec
- On average half the revolution time of the 7200rpm HDD for the actual write, on average ~4.5msec
We are dealing with striped HDDs and the write operation is reported complete to Windows/CDM as soon as write operation has been queued in the L1ARC for the disk. Also all these random asynchronous write operation are collected for 5 seconds, sorted based on the location on the platter and written to the disk in one sequence of operations. Another complicating factor is that those 4K CDM records are compressed by ZFS. It has become to complex to reason about it, you only can measure the end result.
Besides real world performance differs dependent on the content of the caches at each moment in time. E.g boot times between the nvme-SSD and the frequently used, striped and cached HDDs can be as close as 13.8 vs 15.5 secs or it can be 50 secs for Windows 8.1 only booted once many days ago.
Some experimentation with record sizes in host and VM might help with the understanding.